С експоненциалния растеж на Web и на разнообразието на информация, която се предоставя, използването на навигационно-ориентирани браузъри за намиране на специфична информация в Web, се превръща в почти невъзможно начинание. Все по-често потребителите се сблъскват с огромната, разнородна и непрестанно променяща се мрежа. С изключение на постъпковото изучаване, те нямат друг систематичен начин за извличане на информация. С оглед улесняването на търсенето в Web, множество усилия бяха положени за прилагане на техниките с бази данни към Web, включително построяването на индекси, разширяването на езика HTML, възприемането на мета-изобразяващия механизъм, заграждането на ресурси в обекти и установяването на host query сървъри.
Web осигурява глобална вселена от ресурси с хипертекстови връзки, слепени в едно. Очевидно е, че не е достатъчно да се търси информация, базирана само на съвпадението на думи. Въпреки че HTML установява структурите в един документ, той не позволява на семнатичното съдържание на документи да бъде категорично определено. За да се преодолее този проблем, три концепции от базите данни, които се използват заедно: ентити, атрибут и връзка, са представени на HTML. Информацията в Web страниците може да бъде видяна като колекция от ентитита, притежаващи атрибути, които са свързани чрез връзки. Това позволява елементите на един документ да бъдат идентифицирани с елементи от релационните бази данни. По този начин формализма на базите данни може да бъде въведен директно в web страници, което от своя страна позволява на клиент- или сървър- приложенията да извличат информация директно от тях, използвайки способи на релационните бази данни.
Осигуряването на способности от по-високо ниво, за представяне, локализиране и филтриране на поддържаната в Web информация доведе до създаването на SQL (Structured Query Language) като език, поддържащ ефективни процеси над Web. Той се отнася към структурата и съдържанието на Web сайтовете, заедно с техните различни типове асоциирани данни. Този език интегрира новите предимства и съществуващите Unix инструменти (например grep, awk), като по този начин осигурява напредничави възможности за разглеждане на вмъкнатата информация.
По този начин става възможно за разработчиците на приложения да направят пълна употребата на възможностите на HTML за създаване на формите за заявка и доклад, и SQL за заявки и обновявания. Този механизъм се използва за да предостави бърза и лесна конструкция на приложения, който достъпва релационните бази данни чрез CGI (Common Gateway Interface) програми. С дузини интересни, но несъвместими открития от различните аспекти, HTML е претоварен днес и докато той ще продължава да играе огромна роля за съдържанието, което текущо представя, много нови Web приложения изискват по-гъвкава и логична инфраструктура. В отговор на това, World Wide Web Consortium (W3C) разработи опростен диалект на SGML (Standart Generalized Markup Language), наречен XML (Extensible Markup Language), така че да направи възможно SGML предоставен, получаван и процедиращ в Web по начина, по който това е възможно сега с HTML. XML описва един клас от обекти-данни, наречени XML документи и дефинира поведението на компютърните програми. XML документите са направени като единици за съхранение, т.е. ентитита, които съдържат или текст, или двоични данни. Текстовите данни са изградени от символи, някои от които формират markup-а. Той кодира описанието на съхранението в документа и логичната му структура. Докато XML допуска някои комплексни и по-малко използвани части от SGML, потребителите могат лесно да дефинират документи и да пишат приложения, които да ги поддържат.
Освен това, комбинирайки силата на приложенията клиент-сървър с независимостта на платформата, приложенията в Web представят огромните предимства в областта на информационните технологии. "Сватбата" на HTML с компонентите, услугите и скриптовете от сървърната страна (server-side), позволи на разработчиците да създадат Web базирани приложения с големи възможности и за Intranet, и за Internet. Внедряването на директния достъп до базата данни в Web приложенията, от своя страна доведе до развитието на много възможности:
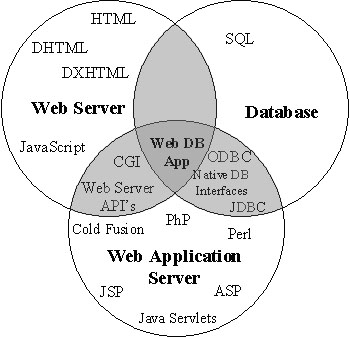
В процеса на разработване на една база данни с всички възможности в Web, дадените по-горе четири елемента могат да се обединят в три основни компонента: база данни, Web сървър и Сървър за приложения (Application сървър). Между всичките три възможни части съществуват интерфейси, както и взаимодействие между целите три компонента. Това може да се види на фугурата по-долу:
Сивите области са мястото, където се простира технологията за бази данни в Web. Трябва да се има предвид, че тези три области не показват, че има замесени три различни инструмента - някои продукти комбинират няколко от тези компоненти в един-единствен "пакет".
А сега за да разгледате по-обстойно всяка от тези подобласти, изберете страница от менюто вляво, или подобласт от менюто горе.